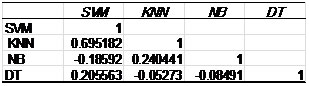
Project Model
The project passes through three main phasesas shown in figure 2
Arabic documents collection
Data preprocessing
Classification
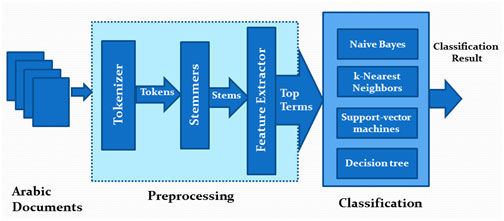
Figure 2: ATC model
Arabic documents collection.
In this phase, we collect the data set that will be used for building and testing the classifier module. At this point we had to make an important decision; whether we will deal with diacritics. As we mentioned earlier, diacritics is very important in Arabic documents, for instance to distinguish between the two words (ذَهَبَ zhb) which means "to go" and the word (ذَهَبْ zhb) which means "gold" , the only way is to depend on diacritics The two words are totally different; "Go" can appear in many contexts without identification for any topic an category, while the word "Gold", when it appears frequently in a document it means that this document could be categorized under financial or economical context.
But on the other hand working with diacritics in documents is very difficult, not only because it increases the character space from 28 letters to more 300 character.But also, diacritics are subjected to many complex Arabic grammars. So, if we want to consider the diacritics we have to consider the Arabic grammar and syntax which is a very complex problem.In the project,we used diacritic-lessdocuments or documents with very little diacritics.
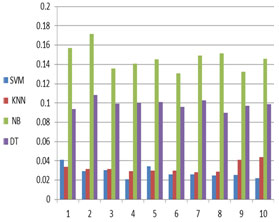
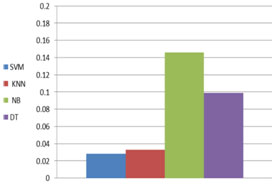
Our document collection consists of one hundred documents all of them are about Arabic spring; these documents are categorized into two main topics; violence and politics in Arabic spring. Each category is 50 documents. We collected these documents from the Arabic news websites. For each of these categories there are many words that are expected to be more frequent, for each category we expect to find a set of frequent words, as well, we expect to find a set of common words for both categories as shown infigure 3.
جغرافي الأنظمة دولي القومي المنطقة الحرية السياسية
Geographic Systems International National Area Liberty Politic
(a)
حرق سلاح ميليشيات مواجهات انفجار قتل عنف
Burn Weapon Militias Clashes Explosion Kill Violence
(b)
مسؤول الشعوب حكومة شارك قرار القوى
Responsible Peoples Government Share Decision Forces
(c)
Figure 3: (a) Some frequent words in politics documents, (b)Some frequent words in violence documents, (c)Some common in violence and politics documents
These documents are located into two subfolders called "Politics" and "Violence" in a "DATA" folder and the path of this folder is passed to the next phase to start working on these documents.
Data pre-processing
In this phase, documents are processed and prepared to be used by the classification phase. This phase has three main sub-phases; Tokenizer, Stemmer, and Feature extractor
Tokenization
Tokenizer is responsible for scanning each document word by word, and extracting words in this document. It has two main steps; tokenization and text cleaning.
In the tokenization, the Arabic Tokenizer uses White Space Tokenization because the space is the only way to separate words in Arabic language, i.e. dash and hyphen are not used to separate words in Arabic. Then in the text cleaning step, it removes the non-Arabic letters, numbers and punctuations as shown in Figure 4.





Figure 4: Tokenization example
It also removes the stop works such as stop words pronouns, conjunctions, and prepositions. As well, it removes numbers, and names.
In Arabic, identifying and removing names is not an easy task like that in other languages.In English for example, the capital letter are used for identifying names and abbreviations in the middle of sentences, while in Arabic, the concept of capital letters does not exist at all. Another problem is that most Arabic names actually come from verbs and could be stemmed to regular stems, also Arabic names and could be used as adjectives or other parts of the sentences. The most suitable technique for identifying names may be based on sentence analysis. But the problem facing these techniques is the complexity of Arabic. i.e. the basic sentence structure for Arabic is very flexible and may take the form of "Subject Verb Object" , "Verb Subject Object" or "Verb Object Subject", the basic Arabic sentence can take any of these three forms. This is a simple example of the complexity of Arabic sentence structure.
The simplest way to detect names in a document is to use a name list, and when the Tokenizer extracts a word it compares it against this list. But this solution is not effective since we need to add all names in this list, as well; it cannot deal with the compound names.
Stemming
The main goal of the stemming is toimprove the efficiency of the classification by reducing the number of terms being input to the classification. As we mentioned earlier, Arabic language is highly derivative where tens or even hundreds of words could be formed using only one stem, furthermore, a single word may be derived from multiple stem. So, working with Arabic document words without stemming results in an enormous number of words are being input to the classification phase. This will definitely increase the classifier complexity and reduce its scalability.
Many stemming methods havebeen developed for Arabic language. These stemmers are classified intotwo categories. The first one is root extraction stemmerlike the stemmer introduced by
The secondis light stemmers like the stemmer introduced by in
.
In this project we used a Rule-Based Light Stemmer introduced in
In this stemmer, to solves the problem of prefix/suffix sequenceambiguity, words are firstly matched against a set of all possible word patterns in Arabic before prefix/suffix truncation, so if a word starts with apossible prefix but itmatched one of the possible patterns, then it’s a validword and this prefix is part of the originaland should not be truncated.
Then, if the word didn’t match any of thepatterns, then the compatibilitybetween the prefix and suffix should be found, where some suffixescould not be combined with certain suffixes in thesame word. If the prefix and suffix are combatable then they could be removed from this word. For example the prefix “ ال ”may not be combined with the suffix “ ك ” so we cannot say “ الكتابك ” and thus if we have a word like“ الكرنك ” the stemmer will not remove the prefix and suffixwhich lead to the wrong word “ كرن ” but it willdetect that the last character “ ك ” is part of theoriginal word and not a suffix, and soit will onlyremove the prefix “ ال ” which will lead to the correctstem “ كرنك”
If the combination of the prefix and suffix is validthen the stemmer counts the letters of the word after removingthe prefix and suffix since Arabic words other thanconjunctions like “ من” ،“في ” consists of at least 3characters. Based on this count it will take the prober decision.
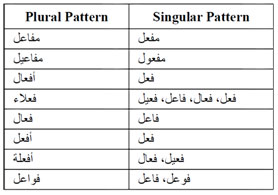
Finally, the stemmer tries to solve the problem of so called broken plural in Arabic, in which, a noun in pluraltakes another morphological form different from its initial form in singular. To do that, the stemmer keeps a table of patterns for all broken plural and their singular form, this table is shown in Table 3.
Table 3 Singular and plural patterns.
The following (figure 5) is the result of the stemming phase in our project for the terms shown in figure 4.

Figure 5: The stemmer output
Feature extraction
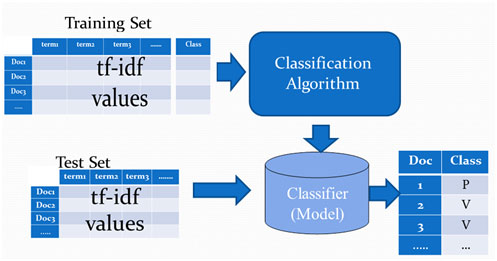
This phase starts by splitting the data set into training set and test set. The size of the test set is determined by a parameter "test_set_ratio".
In this sub-phase, the most informative terms are extracted from documents. There are two main benefits from the feature extraction. The first is that it reduces the number of dimensions(terms) and thus reduces the classifier complexity and processing requirements (Time, Memory, & Desk Space). The second is increasing the classification efficiency by removing noise features and avoid over fitting caused by terms that are frequent in all categories. The extraction is supported by the experiment conducted in
, which illustrates that selecting 10% of features exhibits the same classification performance as when using all the features when using SVM in classification. Based on this argument we use a parameter in the feature selection phase called "feature_ratio" and set it to 10%.
The feature selection can be based on many parameters such as tf.idf, Correlation Coefficient Chi2, and information Gain (IG). In this project we used the tf.idf as selection criteria since it also removes terms which are frequent in all classes thus reducing the over fitting.
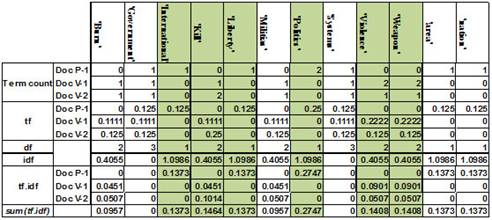
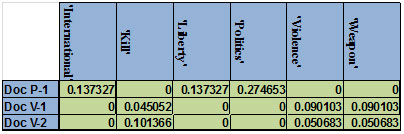
Figure 6-a shows an example of 4 documents (2 politics + 2 violence) and the calculated values for the feature extraction phase, assuming these documents are input to the feature extraction phase.The classifier selects the second document as a test set and the other three as training set. First the term count for each term is calculated, then the term frequency. Then the document frequency and the inverse document frequency (log3/df) are calculated. Finally the tf.idf is calculated as shown in figure 6-b. then to find the highest weighted terms, we sum the tf.idf of each term and the terms with the highest values are selected. In this example we configured the feature_ratio to 50%. The selected features shown in figure 6-c are then passed to the next phase with their classes.
The same calculations are made for the test set except that for the test set we donot need to find the tf.idf for all terms but only for the selected terms

(a)
(b)
(c)
Figure 6: Feature extractionexample
 0%
0%
 Author: Ahmed A. Elbery
Author: Ahmed A. Elbery